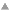So I can vary the number of assignments each op does in the URL.
Experiment 1: just a hundred sequential requests.
$ ab -n 100 "http://127.0.0.1:8080/?iters=10"
On my laptop 98% of requests complete in 3ms.
Experiment 2: let's inch up to 2 concurrent requests at a time.
$ ab -n 100 -c 2 "http://127.0.0.1:8080/?iters=10"
Now 50% of requests require at least 4ms. For 98% it's 10-15ms.
Experiment 3:
ab -n 100 -c 10 "http://127.0.0.1:8080/?iters=10"
Now 50% of requests require 20-40ms.
In general the 50% latency number that apacheBench returns seems to increase linearly with the number of concurrent requests. This rule of thumb has held in my app as well over several major changes. Right now readwarp requests take 800ms on localhost and 2-3s from the internet at large. Not much room for those latencies to grow linearly.
I can't compare your first and last example because one says 98% and the other 50%.
If it were an apples to apples comparison would you agree that it wouldn't be surprising that if the server were handling 10x the number of simultaneous requests that each request would take 10x as long?
The only apples to apples comparison is going from one simultaneous request to two simultaneous requests which has the increase from 3ms to 10-15ms, which seems like about double what we'd expect if using threads had no overhead at all.
When I give just the 98% number I meant the 50% number stays the same (+/- 1ms). We're at the limits of ab's time resolution here.
Yes, none of this is surprising given that PLT is single-threaded. I'm trying to remember my class in queuing theory.. If each request takes m ms to process, n concurrent requests will take mn ms to process, (n-1)m ms of queuing delay and m ms of processing time. The average latency seen would be mn/2 which scales by n. As the number of concurrent requests grows, the curve of latency to number of concurrent requests would be linear.
If you now add a second queue, the curve stays flat until 2 requests and then moves linearly up. Each queue is only n/2 long, so average queuing delay is (n-1)m/4 ms. With q queues, on average there's only (n-1)m/2q ms of queuing delay.
Summary: if you can have multiple truly-concurrent threads, you'll be able to overlap that many concurrent requests without any increase in latency, and the slope of the curve past that point will be inversely proportional to the number of threads. Does this make sense?
---
After I wrote my previous comment I started looking in greater depth into why I'm taking 800ms to process a request. I'm really not doing that much. I'll post an update with what I find. Perhaps I haven't spend enough time attacking m before looking to expand q.
When you say that PLT is "single-threaded", is what you're referring to is that PLT only uses one CPU?
Well, yes, if you have 10 CPU's then you can handle 10 simultaneous requests in the same elapsed time as 1 CPU can handle 1 request. If you don't have any overhead in communication between CPU's, locks, etc.
I think it's clearer to talk about having one CPU or multiple CPU's instead of "truly-concurrent threads" or "thread contention".
You can have multiple threads interleaving on a CPU, and in some systems that support more than one CPU, a thread can run for a while on one CPU and then get moved to running on a different, less busy CPU.
Now if you said that that on one CPU 100 requests one at a time took a total of 300ms to process but 100 requests running interleaved on one CPU took a total of 800ms to process, then we would have evidence that there's too much overhead in thread context switching or some other problem.
I think the quality of the thread implementation has a role to play. When a process waits on IO the OS will find something else to do. I don't know if user-level threads can be that smart, and I don't know if PLT threads are that smart.
Without casting aspersions, it's not just about number of processors. Very few programs avoid IO altogether, and if there's IO some programs will be more clever than others in moving work around.
In a properly working thread system, all threads that aren't waiting for something should be given a fair slice of the available CPU time. In particular, no thread that is ready to run should be blocked or delayed because some other thread is waiting on I/O.
If you are wondering if PLT threads work correctly, isn't this rather easy to test? Do an A/B test with some threads that do some computation with and without some other threads waiting on I/O and see if the runtimes are the same.